
ウェブディレクターとして活動していると、しばしば数十ページにもおよぶウェブページのMETA情報を確認しなければならない。これが結構な手間なのだ。
そんな手間をなくして、極力楽をしようというのが今回の趣旨。
Googleスプレッドシートに、「IMPORTXML」という関数を入力すると、ウェブサイトのあらゆる情報を引っ張ってきてくれる。
title、description、h1、keyword、og title、twitter card など、取得できる情報は多岐にわたる。
私が作ったテンプレートを使用すれば、ページのURLを一括で貼り付けるだけで、すべてのページのMETA情報を一網打尽にできる。
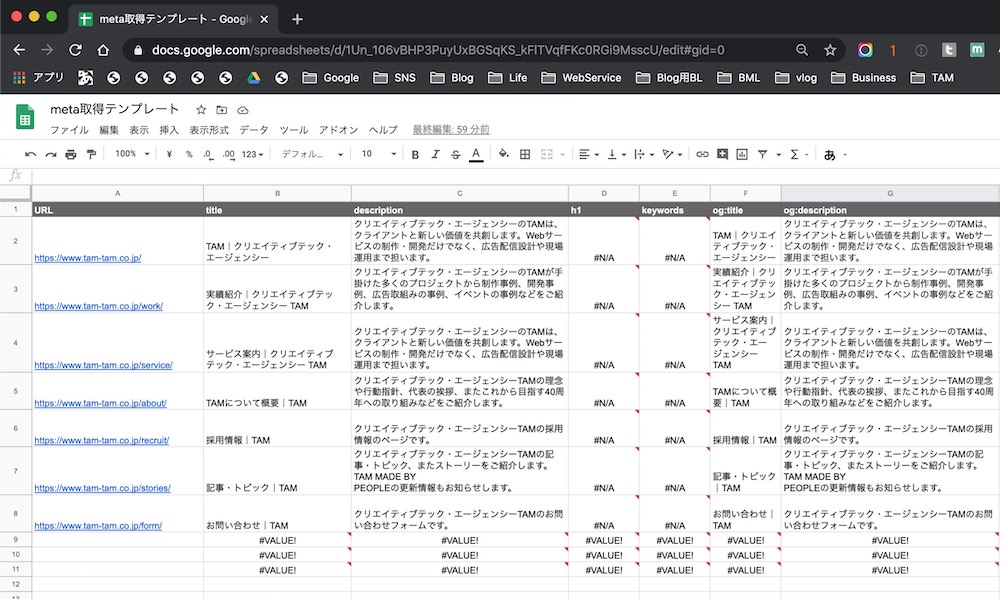
【Googleスプレッドシート】META取得テンプレート
まずは細かい理屈を抜きで、私が作ったテンプレートをご紹介する。
以下のリンクからアクセスすることができるので、ご自身で使うときはシートをコピーして使って欲しい。
META取得テンプレート | Googleスプレッドシート
使い方は簡単。A列に、META情報を知りたいページの URLを貼り付けるだけだ。テキストエディタか何かで、調べたいURLを大量にコピーして、それをペーストするだけでいい。
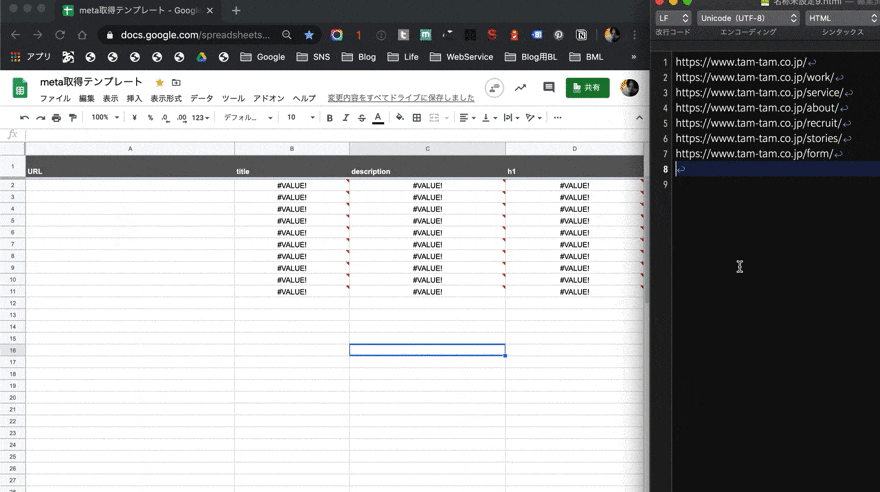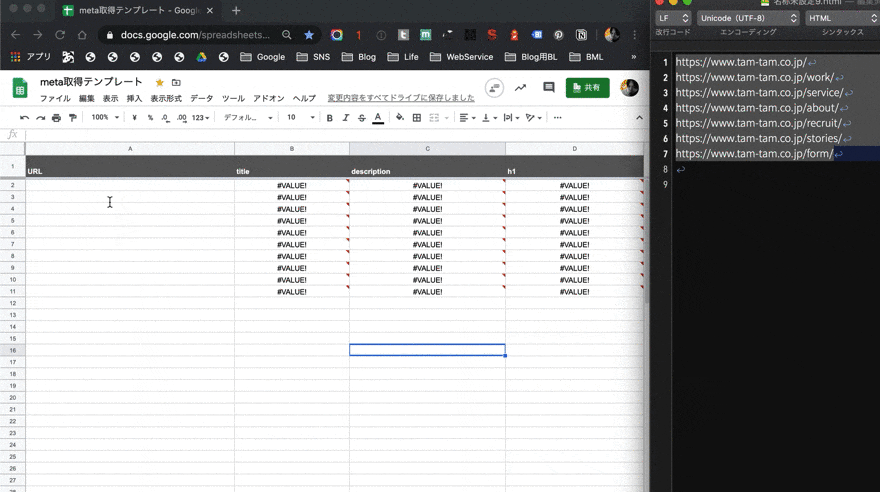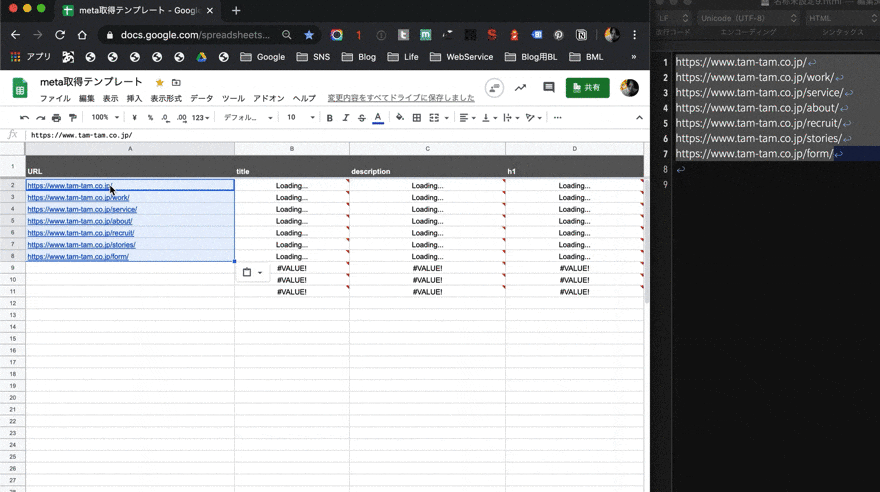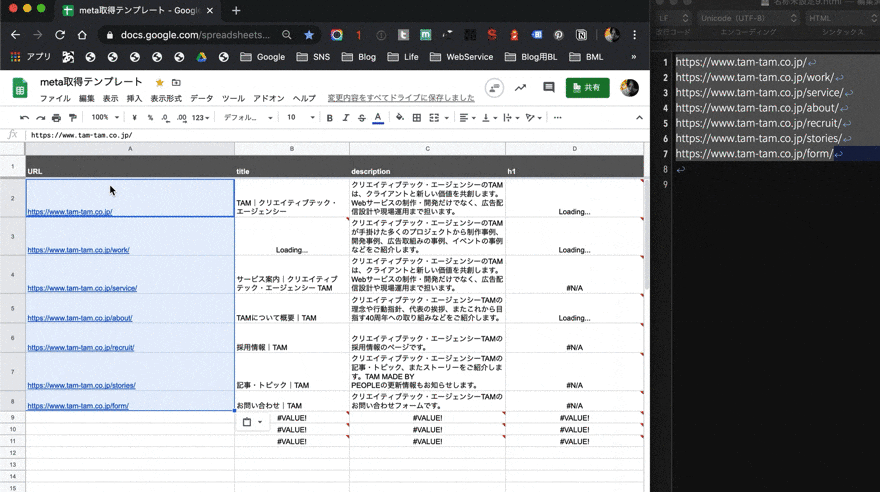
そうすれば後は、自動的にページを解析して、META情報をスプレッドシートに記入してくれる。
難点:Loadingが長引くことも
難点があるとすれば、読み込みが長くなるときがあることか。いつまで経っても「Loading...」が止まらず、時間がかかってしまうことがある。
関数を軽量化するために「ARRAYFORMULA」という関数も試したが、どうやら今回のケースでは適用できないらしい。
そのほかにはキャッシュを削除したりする方法もあるらしいが、根本的な解決にはならなかった。大人しくゆっくり待つしかないらしい。
逆に「こうすれば解決しますよ」という方法をご存知の方がいたら、ぜひTwitterまで一言リプライを飛ばしてもらえると嬉しい。
関数「IMPORTXML」とは
今回使ったのは「IMPORTXML」という関数だ。
その名の通り「XML」を「IMPORT(読み込む)」という意味の関数で、ウェブサイト上のあらゆるデータを引っ張ってくることができる。
引っ張ってこられるデータはさまざまで、代表的なものだと以下のものが挙げられる。
| title | =IMPORTXML(A1,"//title") |
|---|---|
| meta description | =IMPORTXML(A1,"//meta[@name='description']/@content") |
| meta keywords | =IMPORTXML(A1,"//meta[@name='keywords']/@content") |
| H1 | =IMPORTXML(A1,"//h1") |
| meta og:title | =IMPORTXML(A1,"//meta[@property='og:title']/@content") |
| meta og:description | =IMPORTXML(A1,"//meta[@property='og:description']/@content") |
| meta og:type | =IMPORTXML(A1,"//meta[@property='og:type']/@content") |
| meta og:url | =IMPORTXML(A1,"//meta[@property='og:url']/@content") |
| meta og:image | =IMPORTXML(A1,"//meta[@property='og:image']/@content") |
| meta fb:app_id | =IMPORTXML(A1,"//meta[@property='fb:app_id']/@content") |
| meta twitter:card | =IMPORTXML(A1,"//meta[@name='twitter:card']/@content") |
| meta twitter:site | =IMPORTXML(A1,"//meta[@name='twitter:site']/@content") |
| meta twitter:creator | =IMPORTXML(A1,"//meta[@name='twitter:creator']/@content") |
| meta og:site_name | =IMPORTXML(A1,"//meta[@property='og:site_name']/@content") |
| canonical URL | =IMPORTXML(A1,"//meta[@property='og:site_name']/@content") |
これらの関数は、そのままコピペで使ってもらって構わない。「A1」となっている部分に、読み込みたいページのURLの入っているセルを指定してくれればOK。
開いているタブのURLを一気に取得する方法
今回のテンプレートを活用するにあたって、知っておくと便利なChrome拡張機能をご紹介。
Chromeで今開いている全てのタブのURLを一気にコピーする拡張機能
私の調べ物のスタイルとして、気になったページはとりあえず別タブでガンガン開いて、それらの記事を後からゆっくり見ていくのです。そうするとこんな感じで、参考サイトでいっぱいになったChromeができあがり
「Copy All Urls」を使うと、Chromeでいま開いているタブのURLを一括でコピーできる。

調べたいページをとりあえずブワーっと開いて、それを一気にコピー。そのURLをスプレッドシートにペーストすれば、META情報をまとめて取得できる。
あとがき
有料ツールでも同様のサービスはあるが、工夫すれば無料でもさまざまな情報をバッと手に入れることができるものだ。困ったら、諦めるのではなく、まずキチンと調べてみるのが大切やね。
